作为共同内训,我们应该讲一些微朋友都需要了解的通识内容。所以这次我们以日常使用浏览器作为例子,简要介绍用户端和服务器端是如何建立起桥梁的。
第一步:打开一个网页
我们以贵潮官网网站为例:
现在,一个2019年秋纳用的过气网站出现在主页上,这显得非常正常,因为我们平时就是这么用的。
你是否思考过,这个主站它是怎么从服务器上“快递”到你的电脑上的?
第二步:打开开发者工具
现在按下F12进入载具打开新世界。
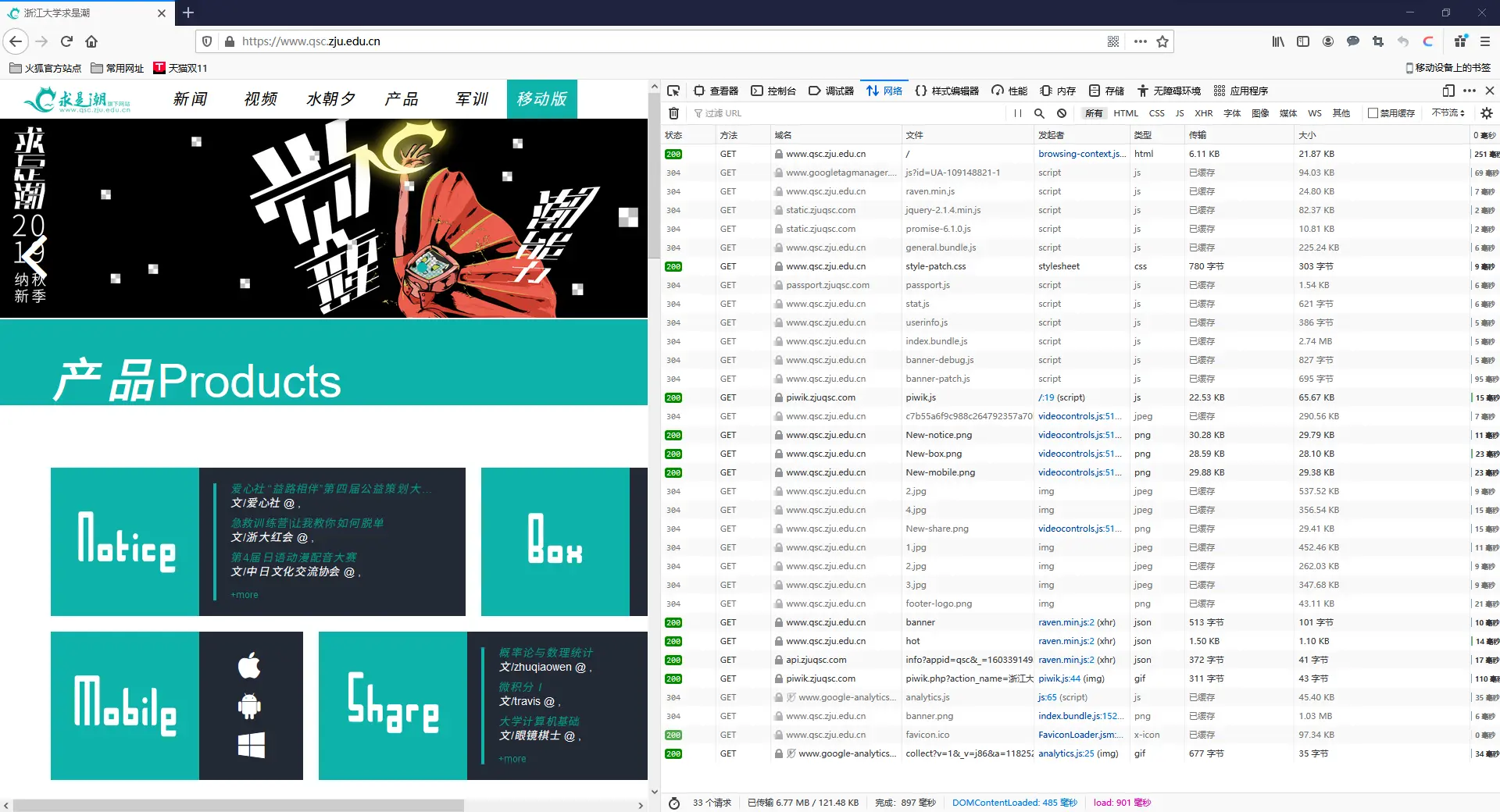
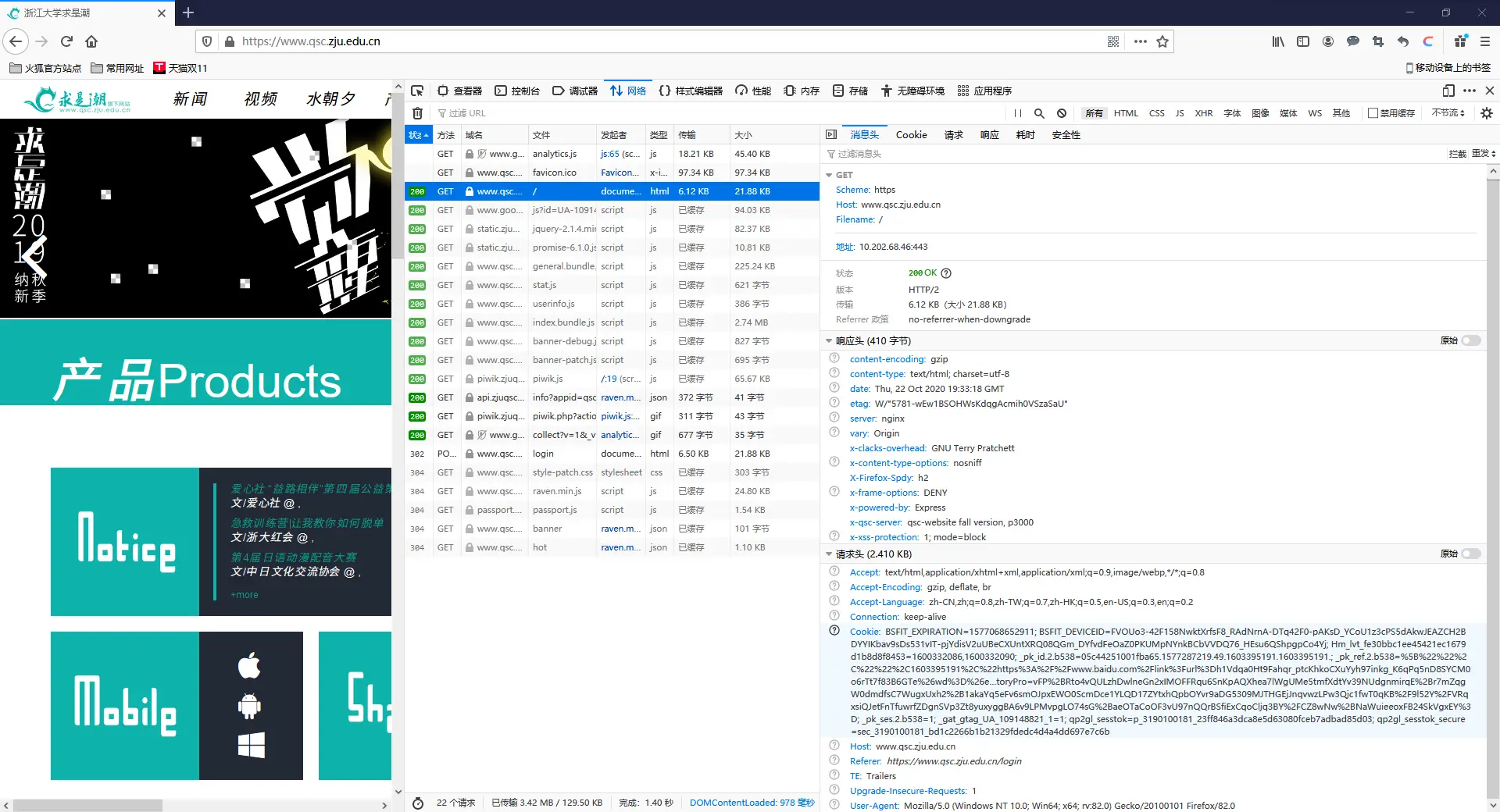
可以发现,在我们尝试访问主站时,浏览器(也就是请求头中的User-agent)向服务器端请求了若干数据,并且最后成功返回(状态码:200)。
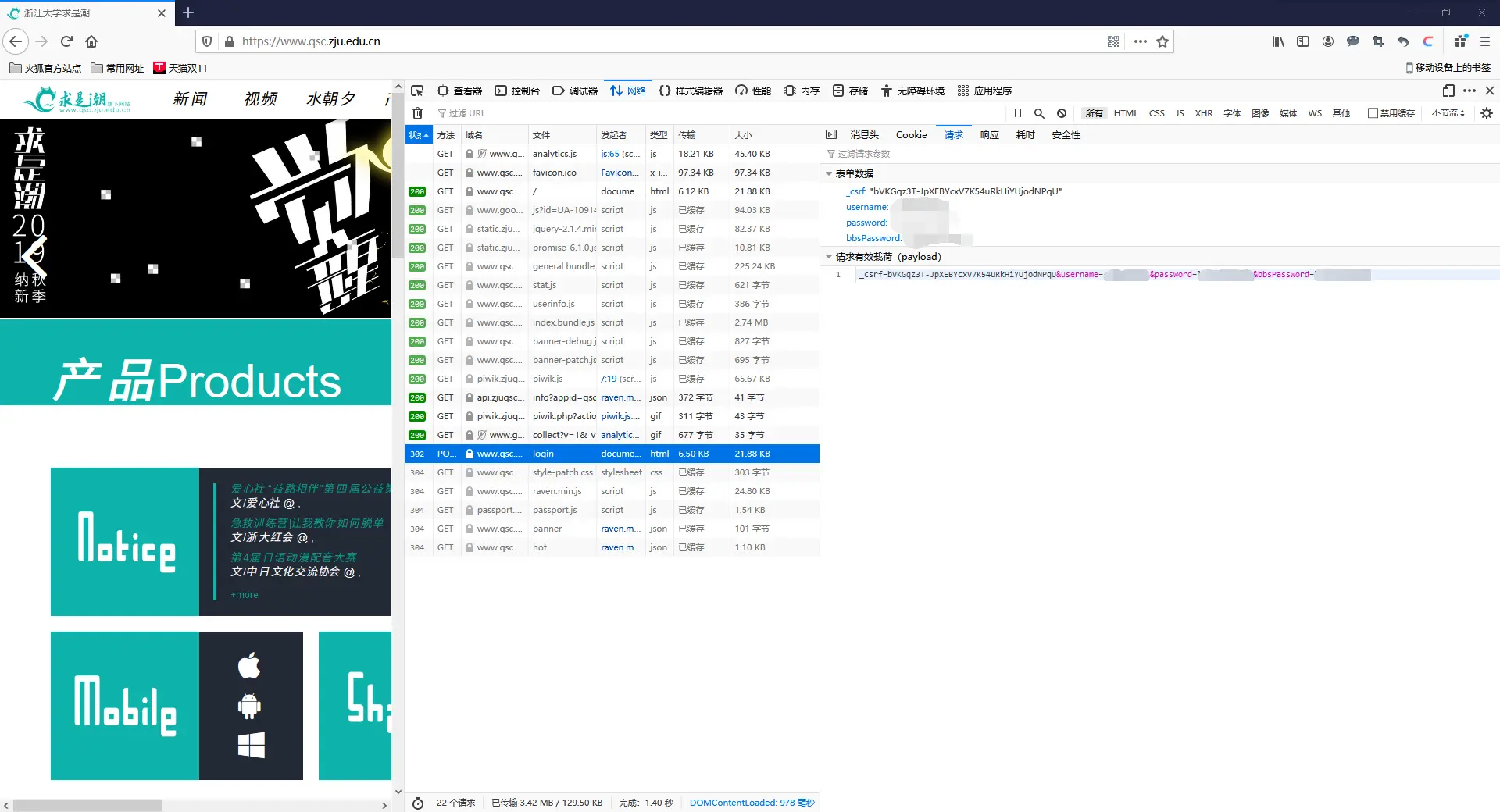
任意点开一栏请求文件,我们可以查看到浏览器究竟请求到了什么:
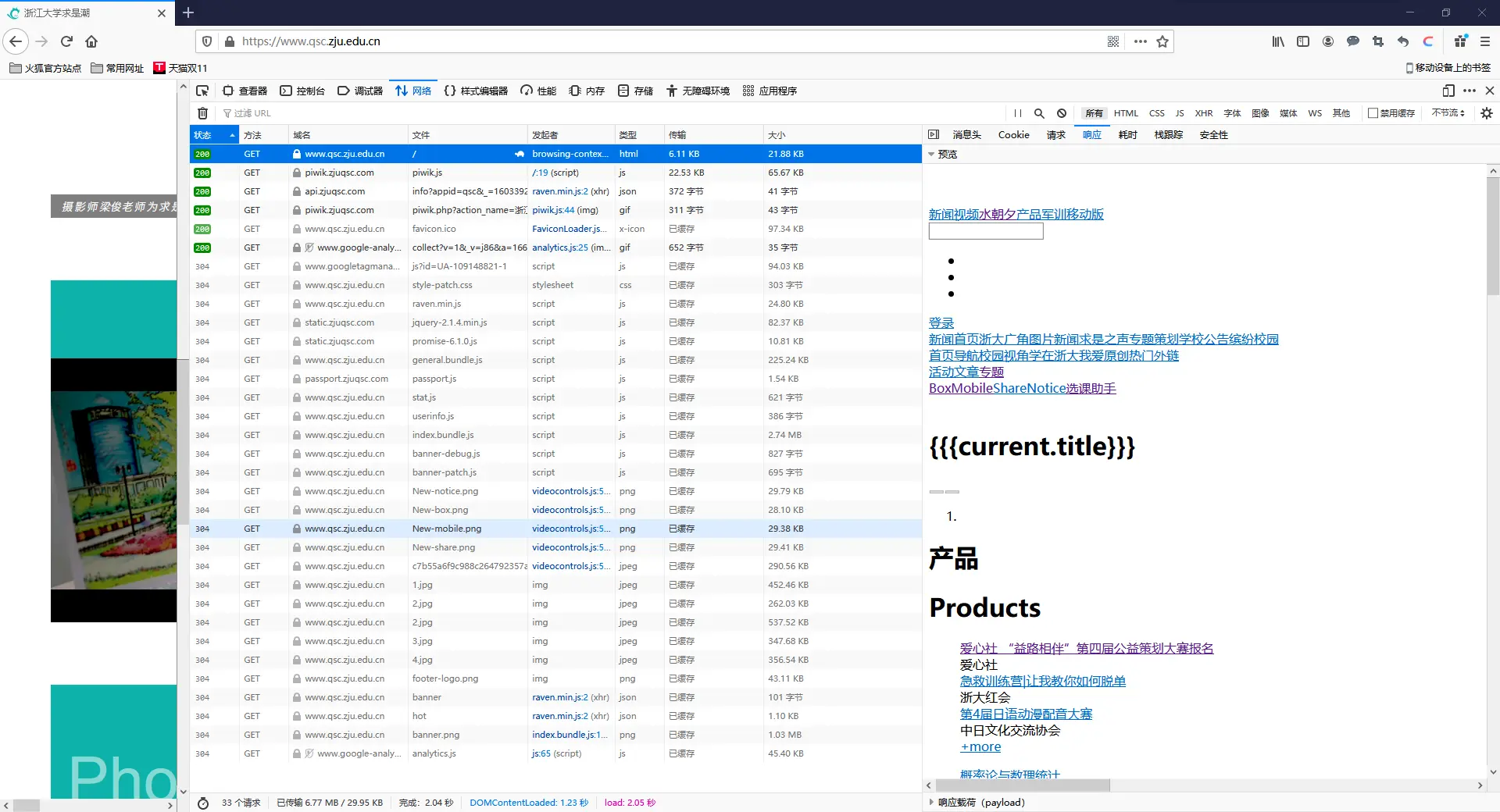
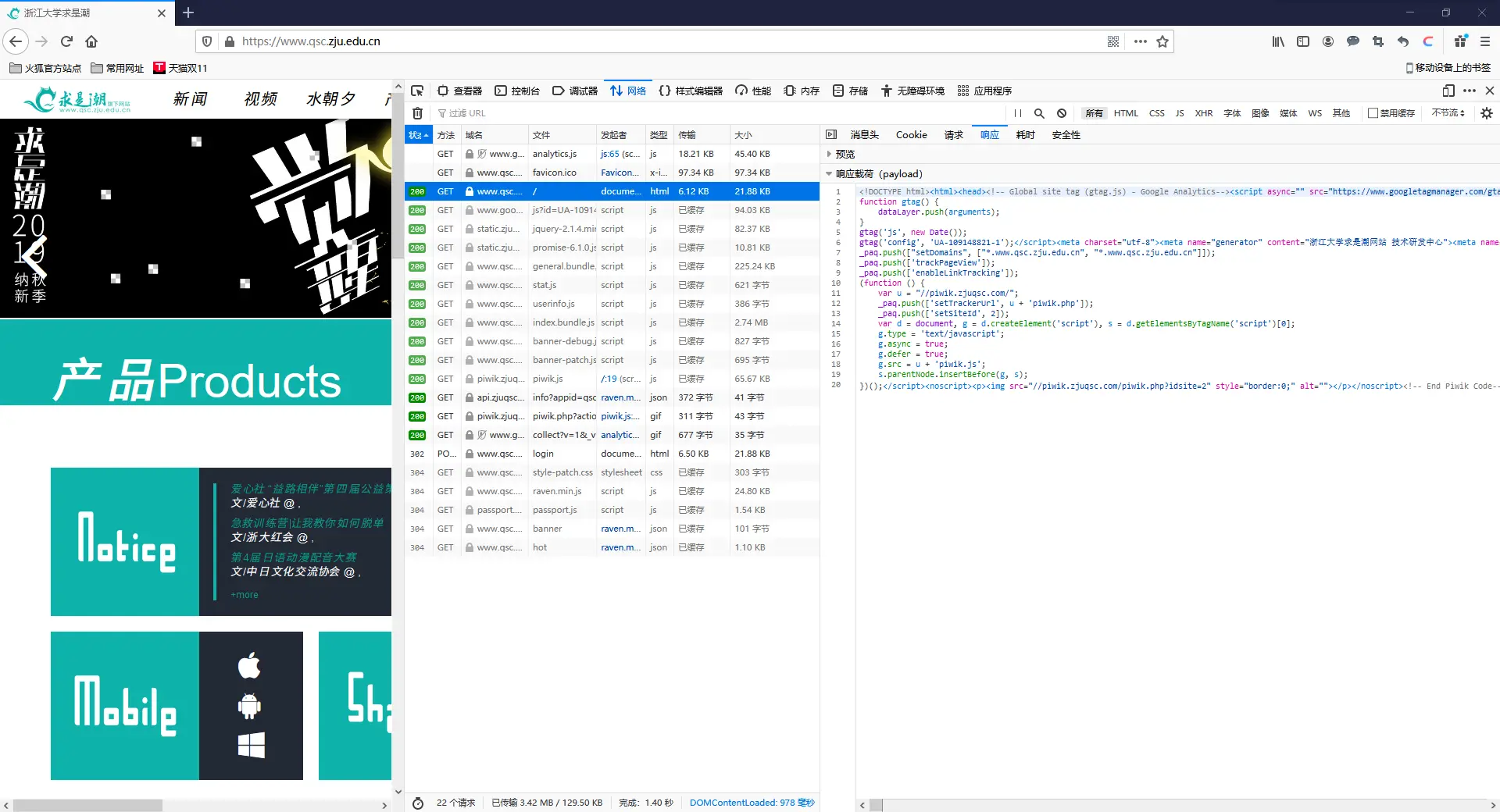
右侧的预览界面看起来完全不像是个正常主页,但它的确是HTML文件的预览,也就是说,没有CSS和JavaScript,我们的求是潮主站就会变成这样。
同理,你也可以依次在这33个请求中找到js、css文件以及网站里需要的各种插图等等,区别在于,有些文件可能已经在之前的访问请求时已经缓存,不需要再重新请求一次。
第三步:发生了什么?
现在我们似乎大致明白了这样一个过程:浏览器向服务器请求数据->服务器按需求把我们数据送货上门。但是这样的请求应当使用什么格式?中间会不会出现丢件?这就是我们接下来想要探究的部分。
HTTP/HTTPS
参考网址:wiki-超文本传输协议
刚刚我们展示的内容,事实上是一个HTTP/HTTPS请求,这两者之间的区别在于HTTPS利用SSL/TLS加密数据包,确保各类型的网页真实,保护账户和保持用户通信,身份和网络浏览的私密性。
简而言之,HTTP(Hyper Text Transfer Protocol)可以帮助我们以一种公认的格式,从服务器处获取资源。
请求过程
客户端发起请求到服务器上指定端口
服务器收到请求
服务器向客户端返回响应消息。
请求/响应信息
请求信息
请求行
在
HTTP/1.1中,一共定义了8个请求方法。请求头
空行
请求数据
响应信息
状态行
消息报头
空行
响应正文
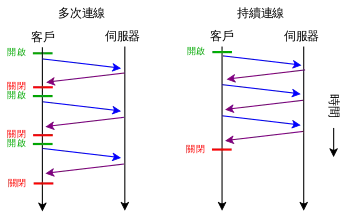
持续连线
在上古版本中,客户端和服务器之间的连接在一次请求/回应之后就会关闭,这显得有些蠢。所以在HTTP/1.1之后我们就有了持续连线机制,这意味着建立起一次连接之后,我们可以进行多次请求,不需要反复进行TCP握手。
TCP/IP
在刚刚的HTTP/HTTPS的简单介绍中,我们实际上完成了一个“填写快递单子”的工作:用一种计算机看得懂的语言按规定好的格式填好收件人姓名地址等信息。但是“快递”会被怎样投递出去?HTTP/HTTPS并不关心这个,它假定下层协议会很好地完成这份工作,这就是我们接下来要谈的TCP/IP。
IP
IP协议作为这次我们所讲的三个协议中最下层的协议,做的就是根据源主机和目的主机的地址来传送数据,大概就是帮我们送数据包裹的快递员。IP协议的独特之处就在于:在报文交换网络中主机在传输数据之前,无须与先前未曾通信过的目的主机预先创建好一条特定的“通路”。正因如此,IP协议提供的是一个不可靠的数据包传输机制(也被称作“尽力而为”或“尽最大努力交付”)。
也就是说,发生如下的事件,IP协议都认为是合理的:
数据损坏
丢失数据包
重复到来
数据包传递乱序:在实际传输数据的过程中,我们可能会把一个大包裹拆成若干个有序的小数据包,分别交给不同的“快递员”送货。当送达顺序和寄出顺序不同时就被称作
数据包传递乱序
这实在太不靠谱,所以我们需要一个物流管理系统控制这一糟糕的送货过程,这也就是TCP协议。
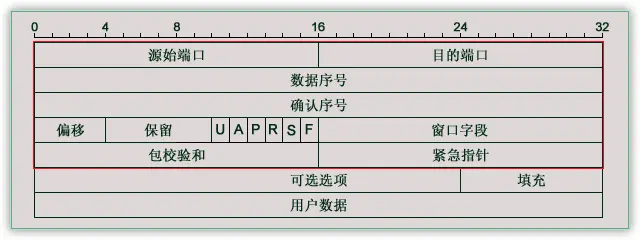
数据包结构

P.S. IP寻址和路由这次暂且不讲,以免坑挖的太大。
TCP
TCP层是位于IP层之上,应用层之下的中间层。正如上文所提,TCP要做的,就是让不太靠谱的IP协议变得靠谱。
运作过程
创建通路:三次握手
传输数据:为了保证TCP的可靠性,在该过程中存在很多重要机制
序号/确认号:TCP报文发送者称自己的字节流的编号为序号(sequence number),称接收到对方的字节流编号为确认号。在接收数据包后,接收者会按照序号重建原本的顺序,同时发送确认包,告诉寄出方已经成功接收的数据流字节位置。
无错传输:通过校验和计算和检验来验证报文的完整性和正确性
丢包重传
超时重传
流量控制
拥塞控制
终止连接:四次握手
数据包结构