
DL-FWI内训Day2
DL-FWI数据结构
进行深度学习训练的第一步是厘清数据集的基本结构。
对于一个地震数据集,存在以下结构关系:
1 | dataset |
在上述的数据集中,共有个单元数据对,每个单元数据对包含速度模型和地震数据。其中速度模型的分辨率为,地震数据包含炮产生的剖面,每个剖面的分辨率为,代表了时间(Time)和接收点(Receiver)数量。
常见的FWI数据集
SEG盐体数据
SEG盐的数据描述了一个大约的地下二维剖面区域. 采样后, 地下的像素区域大小为. 波在这个地下区域的传播速度为。
实际上, 这个SEG盐数据是现实地下盐层三维分析数据通过剖面切片获得的, 共获得了140个切面数据。
模型由SEG研究委员会建立, 大部分的计算是在Sandia和Los Alamos国家实验室完成的。
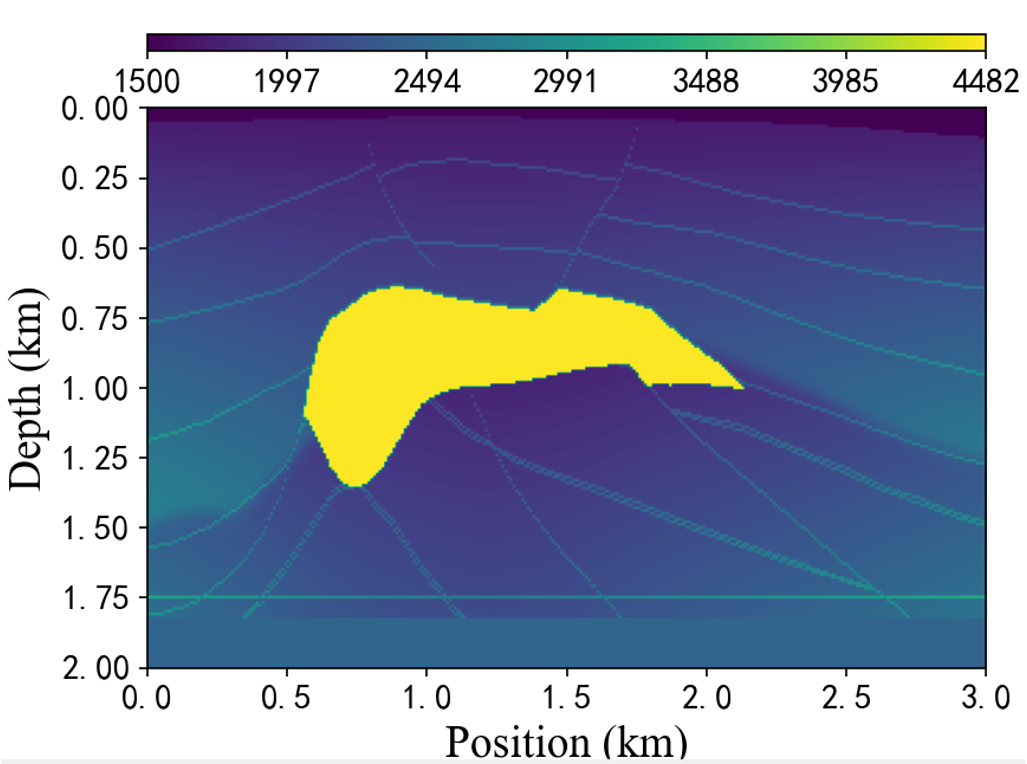
SEG盐体模拟数据
由于真实数据量是很匮乏的, 而DL-FWI的一般网络都是非常吃数据量的模型, 故还需要通过合成一些同SEG盐数据类似分布的模拟数据来进行预训练, 作为网络背景。
模拟数据集有1700个与SEG盐数据大小相同的合成速度模型。每幅图像都有不同宽度的层,从大约5到12层不等。为了精确模仿盐体, 每个速度模型在中间或底部随机嵌入了随机形状的盐体。同时,模拟数据的地层速度波动也控制在。
该模拟数据最早出现于FCNVMB提供的开源数据。
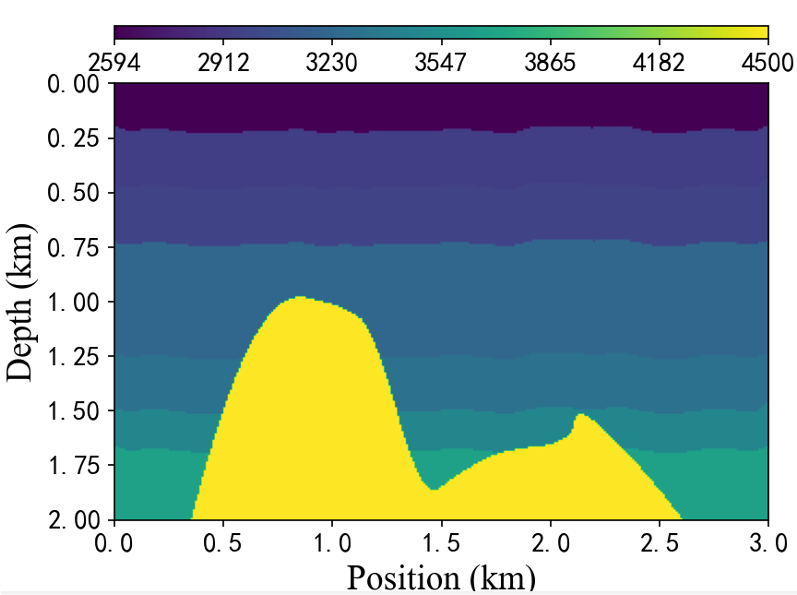
对比这两种模型,真实模型的构造更加复杂,会在观测范围内出现更多的反射波。
OpenFWI数据集
OpenFWI是近一两年随着DL-FWI的蓬勃发展而诞生的大规模、多结构基准数据集的集合。
它包含了12 个根据不同先验合成的数据集,其中包括一个 3D 数据集。而这12个数据集又可以细分为四类数据,Vel类、Fault类、Style类和Kimberlina类。除Style外,它们都表示不同的地下结构,Style则为一种自然图像的迁移假想地层。其中每一种类又可以分为A、B两类,A/B代表地层的难度分级。
OpenFWI数据集的体量非常庞大。同时,官方提供的每个速度模型对应的地震数据并没有经过下采样,因此时间域与宽度的比例非常大。在实际使用的时候,需要对数据进行下采样。
数据输入
FWI的数据暂时没有统一的格式,其中就包括了.npy和.mat格式,导入方式如下例所示:
1 | # .mat format |
